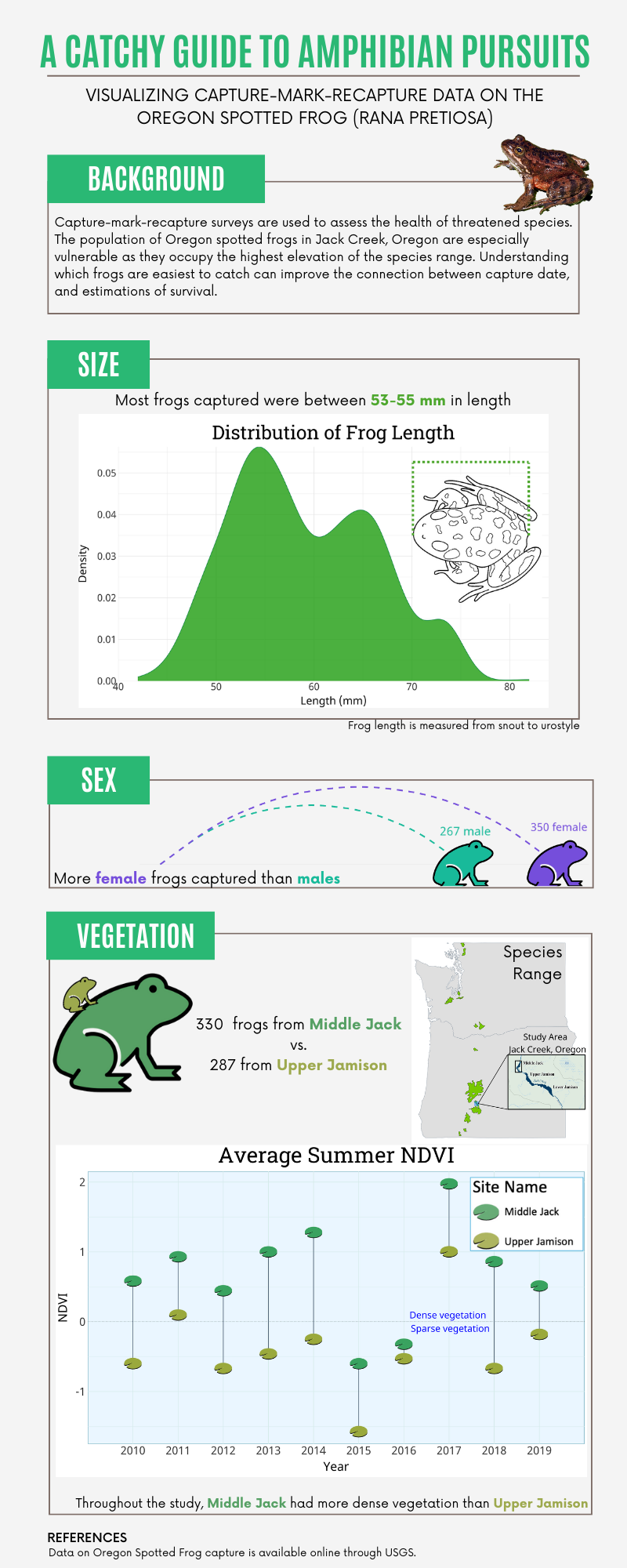
The capture-mark-recapture technique (herein CMR) is a common surveying technique used to calculate estimations of populations or survival over time. As with many mathematical analyses, there are some assumptions that much be met to calculate survival using CMR data. The data used for my infographic was used in a publication that commented on the species survival over several years (Rowe et. al). To calculate survival, it is assumed that the likelihood of catching any individual is the same for all individuals in the population. With this in mind, I created several visualizations that answer the question, what factors affect how easy it is to capture a frog?
About the Data
For the final visualizations, I used two different data frames within the same data publication by the United States Geological Survey (USGS). The first data frame contained the data on CMR surveys of the Oregon Spotted frog (Rana pretiosa) from 2009-2021. The raw data was in “long” format, where every year and visit number were an individual column of 0s and 1s, indicating whether or not an individual was captured. Using pivot_longer , I split year and visit number into individual columns. This allowed me to easily sum the data so that I could count the number of frogs detected based on particular groups (reach, sex, and size).
The second data frame contained data on environmental variables around the time the surveys were conducted. I only focused on the NDVI column in this data set, as I hypothesized that vegetation density might impact the ease of catching frogs. The U.S. Fish & Wildlife service also hosts a geographic data set with the species range of several threatened, and endangered species. I used the species range data to create a custom range map for the infographic.
Read in data
View Code
## ========================================## Read in Data ----## ========================================# set data directorydata_dir <-"/Users/bri_b/Documents/Work/bb-website/bbarajas429.github.io/blog-posts/2024-03-12-frog-infrographic/data"# read frog data ----frogs_raw <-read_csv(here(data_dir, "frog_cmr", "cmrData.csv")) %>%clean_names()# read water data ----env_raw <-read_csv(here(data_dir, "frog_cmr", "waterCov.csv"))# species range data ----query <-"SELECT * FROM usfws_complete_species_current_range_2 WHERE SCINAME='Rana pretiosa' "range_map <-st_read(here(data_dir, "usfws_complete_species_current_range","usfws_complete_species_current_range_2.shp"),query = query) %>%st_make_valid() %>%clean_names()# full state maps ----state_map <-st_read(here(data_dir, "cb_2018_us_state_500k", "cb_2018_us_state_500k.shp")) %>%st_make_valid() %>%clean_names() %>%filter(name =="Oregon"| name =="Washington")# create a coordinate point for data collection areadata_location <-data.frame(lat =c(43.224875),lon =c(-121.587244)) %>%st_as_sf(coords =c("lon", "lat"), crs =st_crs(state_map))## ========================================## Read in Images ----## ========================================# frog icons ----frog_female <-here(data_dir, "frog-female.png")frog_male <-here(data_dir, "frog-male.png")# jack creek map ----creek_img <- png::readPNG(here(data_dir, "jack-creek-inset.png"), native =TRUE)# sul image ----sul_img <- png::readPNG(here(data_dir, "sul-measurement.png"), native =TRUE)# lilypad image ----yellow_pad <-here(data_dir, "yellow-pad.png")green_pad <-here(data_dir, "green-pad.png")# lilypad legend ----lilypad_legend <- png::readPNG(here(data_dir, "lilypad-legend.png"))
Data Wrangling
View Code
## ========================================## Wrangle environmental data ----## ========================================env <- env_raw %>%# select sites of interest (most surveyed)filter(reach =="Middle Jack"| reach =="Upper Jamison")## ========================================## Wrangle frog CMR data ----## ========================================frogs <- frogs_raw %>%# filter to most surveyed reachesfilter(reach =="Middle Jack"| reach =="Upper Jamison") %>%# pivot to split year from detected columnpivot_longer(cols =5:43,names_to ="year_visit",values_to ="frog_detected") %>%# split year and visit number into two columns %>% separate(year_visit, c("year", "visit"),'_') %>%# remove x that precedes the year (x2010, x2011)mutate(year =str_remove(year, 'x')) %>%# rename size to include unitsrename(sul_mm = sul) %>%# remove years w/no frog surveys at Upper Jamisonfilter(year %in%c(2009:2019))# clean environmentrm(env_raw, frogs_raw, query)
Creating Data Visualizations
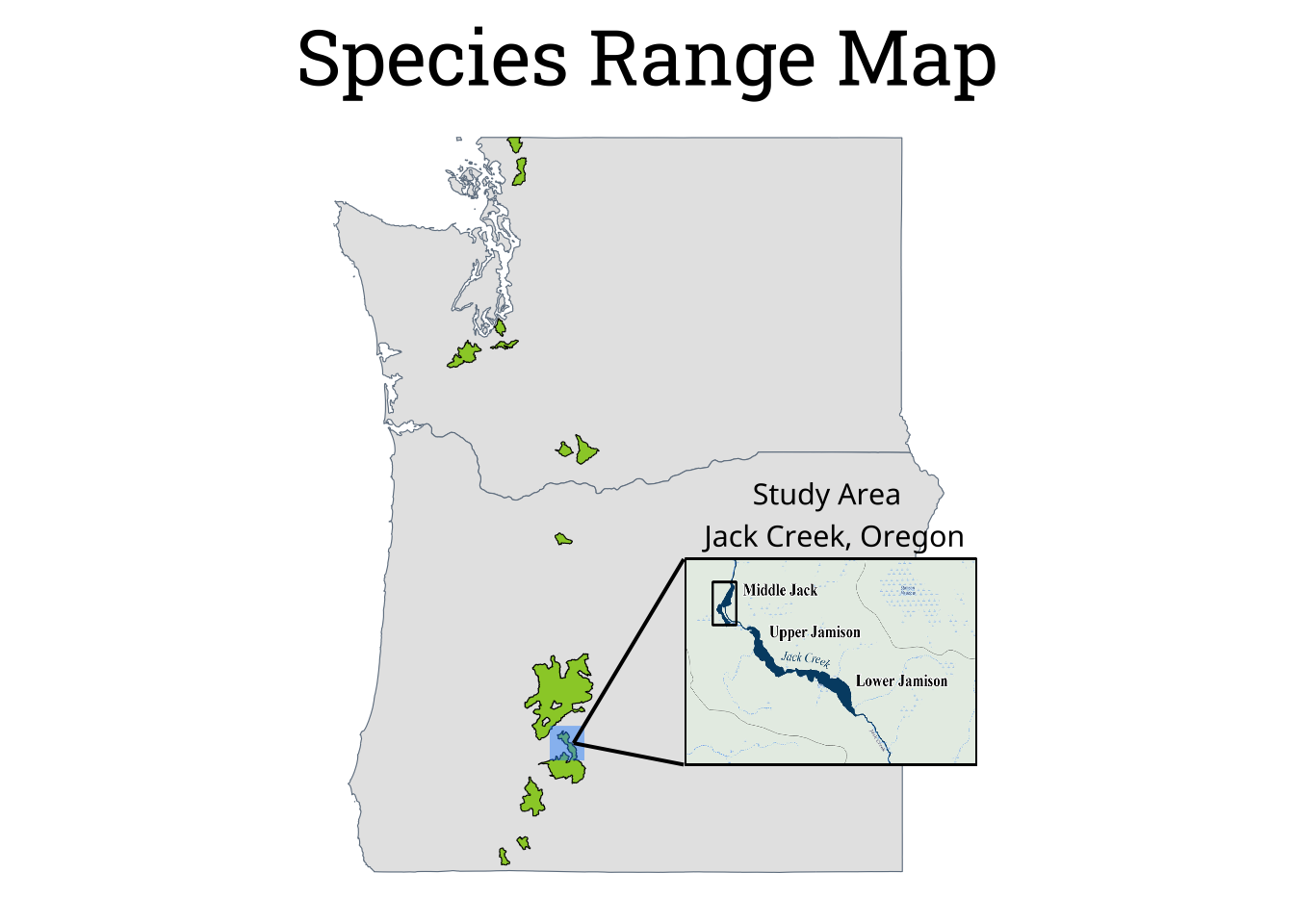
Species Range Map
The species range map was not one of the key visualizations, and required minimal data wrangling. The USFWS dataset included ranges for all threatened or endangered species, so I used a query to select only the Oregon Spotted Frog range. To better demonstrate the study area, I added an inset map with labeled locations of interest. This map is an image from the original publication and has the site names clearly labeled which would be important for the “vegetation” figure.
View Code
# create species range mapggplot() +# map states & species rangegeom_sf(data = state_map, col ="slategray") +geom_sf(data = range_map, fill ="yellowgreen", col ="black") +# add box around study area geom_sf(data = data_location, shape =15, size =6, col ="dodgerblue",alpha =0.45) +# add text annotation for study areaannotate(geom ="text", x =-118, y =45.4, label ="Study Area \n Jack Creek, Oregon", family ="noto", size =4, col ="black") +# expand axis limits so inset image does not get croppedcoord_sf(xlim =c(-125, -116), ylim =c(41.5, 49.5), expand =FALSE) +# add lines connecting study area to inset mapgeom_curve(aes(x =-120, xend =-121.50,y =44.98, yend =43.224875),curvature =0, col ="black", linewidth =0.7) +geom_curve(aes(x =-120, xend =-121.50,y =43.02, yend =43.224875),curvature =0, col ="black", linewidth =0.7) +# add map of study areaannotation_raster(creek_img, xmax =-120, xmin =-116,ymax =45, ymin =43) +# update general theme to remove backgroundtheme_void() +# add titlelabs(title ="Species Range Map") +# adjust title theme and sizetheme(plot.title =element_text(hjust =0.5, vjust =0, family ="roboto", size =30))
Males vs. Females
Since I was comparing counts, I decided I would create a unique version of a bar chart. I was originally looking at lollipop charts when I got the idea to connect the point to a curved line, so it appeared as though the frog was jumping. Since the data presented in this plot was so simple, I wanted to remove as many of the plot elements as possible. For example, instead of a legend I directly wrote out the frog counts by each point. I also made the male and female frog different colors, which I kept consistent in the final inforgraphic caption. Additionally, after calculating the sum I changed the sex column to be the same character string so both frogs would both be on the same axis.
View Code
## ............. Data Preparation..................# create data subset of male vs. female frogs capturedmf_count <- frogs %>%group_by(sex) %>%summarise(frog_catch =sum(frog_detected))# add column with male/female frog imagesmf_count$image <-c(frog_female, frog_male)# change sex to same value so frogs can be on the same linemf_count$sex <-"A"## ..................Plot..........................# create plot of male vs. female frogs caughtggplot(data = mf_count) +# add images of frogs for male and femalegeom_image(aes(x = frog_catch, y = sex, image = image), size =0.2) +# add hop line for malesgeom_curve(aes(x =0, xend =267, y =1, yend =1), linetype =2,curvature =-0.4, col ="#18BA9A", linewidth =1) +# add hop line for femalesgeom_curve(aes(x =0, xend =350, y =1, yend =1), linetype =2,curvature =-0.4, col ="#754edb", linewidth =1) +# expand x-axis to add space for textcoord_cartesian(xlim =c(0, 360)) +# pre-set themetheme_minimal() +# customize labels and titlelabs(title ="Sex of Captured Frogs") +# add labels for data pointsannotate(geom ="text", x =342.5, y =0.87, label ="350 female frogs", family ="noto", size =4, col ="#754edb") +annotate(geom ="text", x =259, y =0.87, label ="267 male frogs",family ="noto", size =4, col ="#18BA9A") +# remove gridlinestheme(panel.grid.major.x =element_blank(),panel.grid.minor.x =element_blank(),# remove labels that aren't neededaxis.text.x =element_blank(),axis.title.y =element_blank(),# customize fontsplot.title =element_text(family ="roboto", size =30,hjust =0.5, vjust =-9.5),axis.text.y =element_blank(),axis.title.x =element_blank())
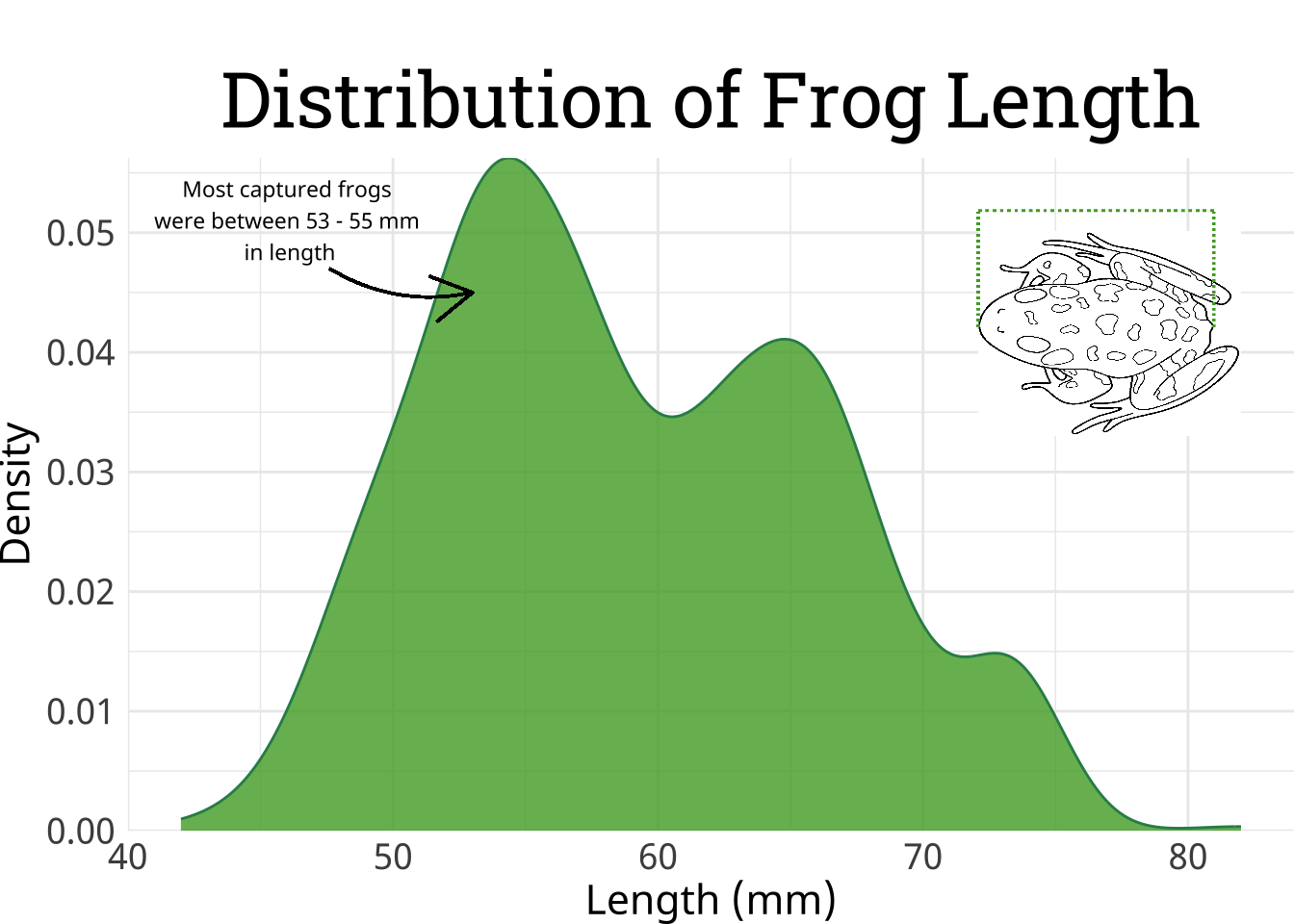
Size Distribution
Since frog size is a continuous variable, I wanted to focus on which sizes were most common instead of calculating totals. Ideally, the distribution of frogs caught would be normally distributed, so I used arrows and notes to highlight where this was not the case. I chose the green color to continue the frog theme, and kept all my annotations black so they popped against the white background. I decided to keep the gridlines so the two peaks could be easily compared. Different species have different standards for being measured, so I wanted to include an image that shows how the frogs were measured. Frogs are measured from snout to urostyle. Instead of defining urostyle, I summarized this measurement as “length” for simplicity.
View Code
## ............. Data Preparation..................# subset to only include frogs that were capturedfrogs_subset <- frogs %>%filter(frog_detected ==1)## ..................Plot..........................# plot density of frog sizeggplot(frogs_subset, aes(x = sul_mm)) +geom_density(fill ="#4EA72E", col ="seagreen", alpha =0.8) +# change standard themetheme_minimal() +# update axis titleslabs(y ="Density", x ="Length (mm)",title ="Distribution of Frog Length") +# update text font and sizetheme(axis.title =element_text(family ="noto", size =16),axis.text =element_text(family ="noto", size =14),plot.title =element_text(family ="roboto",hjust =0.5, size =30, vjust =1),# increase plot marginplot.margin =margin(1,0,0,0, "cm")) +# update plot to start at y-axisscale_y_continuous(expand=c(0, 0)) +# add arrow pointing to most common sizesgeom_curve(aes(x =47.6, xend =53,y =0.047, yend =0.045),curvature =0.2, arrow = grid::arrow()) +# add note on common frog sizesannotate(geom ="text", family ="noto", size =3,label ="Most captured frogs\n were between 53 - 55 mm \n in length",x =46, y =0.051) +# add image for measuring frog lengthsannotation_raster(sul_img, xmax =82, xmin =72,ymax =0.052, ymin =0.033)
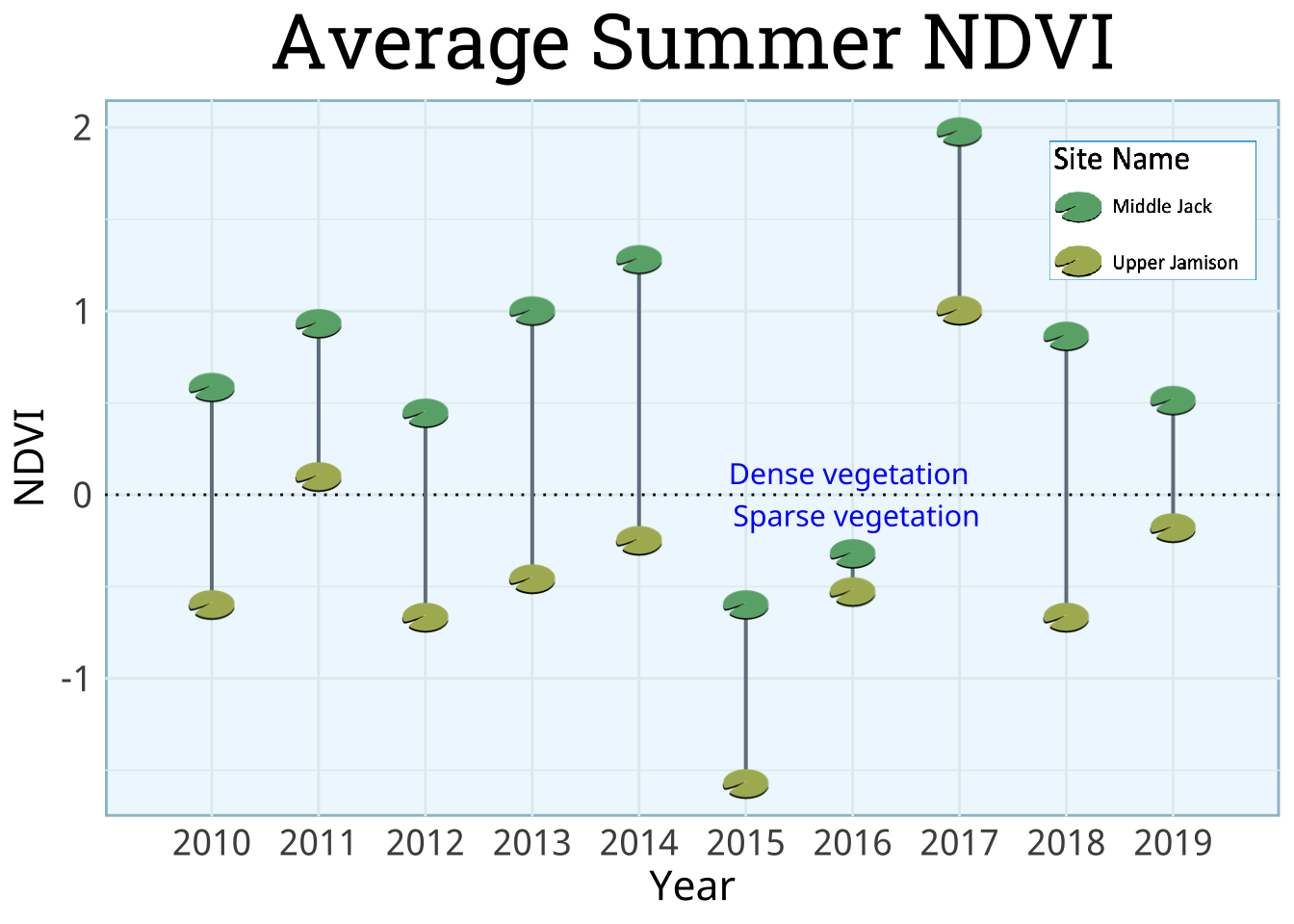
Vegetation
For vegetation, I wanted to highlight several parts of the data including year, average summer normalized difference vegetation index (NDVI), and frog count. To avoid overly complex figures, I decided to focus only on NDVI over time and compare frog counts directly within the graphic. I originally created a line graph that demonstrated NDVI over time for both sites. I decided against this, because I was more interested in displaying the difference not changes. Instead of the line graph, I opted for a dumbell plot to better demonstrate theses differences. I wanted the data points to look like lilypads in a pond. Since Middle Jack has more dense vegetation (higher NDVI), I made the leaf more green than the one for Upper Jamison. I also know that NDVI is not an intuitive variable, so I added a line at 0 and text highlighting that values above zero indicate more dense vegetation.
View Code
## ............. Data Preparation..................# prepare NDVI data for dumbell plotenv_db_data <- env %>%filter(year <=2019) %>%select(c("year", "mdNDVI", "reach")) %>%pivot_wider(names_from = reach, values_from = mdNDVI) %>%clean_names() %>%mutate(year =as.factor(year),leaf = green_pad,dry_leaf = yellow_pad)## ..................Plot..........................# create dumbell plot of annual NDVIggplot(env_db_data) +# add line for 0 axisgeom_hline(yintercept =0, linetype =3) +# add lines to connect NDVI of different sitesgeom_segment(aes(y = middle_jack, yend = upper_jamison,x = year, xend = year), linewidth =0.7, col ="slategray") +# add points as imagesgeom_image(aes(x = year, y = middle_jack,image = leaf), size =0.08) +geom_image(aes(x = year, y = upper_jamison,image = dry_leaf), size =0.08) +# change to standard themetheme_minimal() +# update axis names and titleslabs(y ="NDVI",x ="Year",title ="Average Summer NDVI") +# update theme# update background and grid colortheme(panel.background =element_rect(fill ="aliceblue",color ="lightblue3",linewidth =1),panel.grid.major =element_line(color ="azure2"),panel.grid.minor =element_line(color ="azure2"),# update fonts and text sizeplot.title =element_text(family ="roboto", size =30, hjust =0.5),axis.title =element_text(family ="noto", size =16),axis.text =element_text(family ="noto", size =14)) +# add annotation to provide information for NDVIannotate(geom ="text", size =4, family ="noto",label ="Dense vegetation \n Sparse vegetation",x =7, y =0, col ="blue") +# add legend annotation_raster(lilypad_legend, xmin =8.7, xmax =11,ymin =2, ymax =1.1) +# increase x-axis lengthcoord_cartesian(xlim =c(0,11)) +# increase spacing between x-axis ticksscale_x_discrete(expand =c(0, -11))
Infographic
After creating my plots in R, I switched over to Canva to create the final infographic. Unfortunately, I realized that I had not considered some of the requirements for exporting images using ggsave. Instead of updating the code, I decided to adjust some of the final titles and images in Canva. Since my overarching question is not clear using visuals alone, I started my infographic with a short background section.
Citation
BibTeX citation:
@online{barajas2024,
author = {Barajas, Briana},
title = {Creating an Infographic Using {Oregon} Spotted Frog Capture
Data},
date = {2024-03-12},
url = {https://github.com/briana-barajas/oregon-frog-infographic},
langid = {en}
}